Hbase是什么
HBase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统。它利用Hadoop HDFS作为其文件存储系统,并提供实时的读写的数据库系统。HBase的设计思想来源于Google的BigTable论文,是Apache的Hadoop项目的子项目。它适合于存储大表数据,并可以达到实时级别。HBase不同于一般的关系数据库,它基于列而不是基于行的模式,并且主要用来存储非结构化和半结构化的松散数据。
HBase的扩展性主要体现在两个方面:一是基于运算能力(RegionServer)的扩展,通过增加RegionServer节点的数量来提升HBase上层的处理能力;二是基于存储能力的扩展(HDFS),通过增加DataNode节点数量对存储层进行扩容,从而提升HBase的数据存储能力。
总的来说,HBase是一个功能强大的分布式存储系统,适用于处理大规模、实时、非结构化的数据。
为什么要使用Hbase
使用HBase的主要原因可以归结为以下几点:
-
面向列的存储:传统的关系型数据库(RDBMS)是面向行的存储,而HBase是面向列的存储。这种设计使得HBase在读取数据时只需要读取感兴趣的列,而不是整行数据,从而大大提高了读取效率。同时,列式存储也更适合于稀疏数据的存储,因为它只存储实际存在的数据,减少了存储空间的使用。
-
可扩展性:HBase是分布式存储系统,可以很容易地通过增加节点来扩展其存储和计算能力。这种扩展性使得HBase能够处理PB级别的数据,并应对高并发的读写请求。
-
实时性:HBase提供了实时的读写能力,使得数据可以被快速地插入、更新和查询。这对于需要实时分析或处理大量数据的场景来说非常重要。
-
容错性:HBase建立在Hadoop HDFS之上,继承了HDFS的高容错性。数据在HBase中会被复制并存储在多个节点上,即使部分节点出现故障,数据也不会丢失,保证了数据的可靠性。
-
灵活性:HBase支持动态列,这意味着列可以在运行时添加或删除,而无需预先定义表结构。这种灵活性使得HBase能够适应不断变化的数据需求。
-
社区支持:HBase是Apache的一个开源项目,有着庞大的用户群体和活跃的开发者社区。这意味着当遇到问题时,可以很容易地找到解决方案或得到社区的帮助。
-
与Hadoop生态集成:HBase与Hadoop生态系统中的其他组件(如MapReduce、Spark等)紧密集成,可以方便地利用这些组件进行数据处理和分析。
综上所述,HBase的这些优势使得它成为处理大规模、实时、非结构化数据的理想选择,广泛应用于大数据处理、实时分析、日志存储等领域。
什么时候可以用Hbase
HBase在以下场景中特别适用:
-
大数据存储:当数据量非常大,达到PB级别时,传统的关系型数据库可能无法满足存储需求。HBase作为分布式存储系统,可以轻松地扩展存储能力,处理大规模数据。
-
实时读写:对于需要实时或近乎实时地处理大量数据读写操作的场景,HBase的实时性能力使其成为一个很好的选择。它可以迅速响应读取和写入请求,满足实时分析、日志记录等需求。
-
列式存储需求:当数据具有稀疏性,或者只需要读取特定列的数据时,面向列的存储方式更加高效。HBase的列式存储设计可以减少不必要的I/O操作,提高查询效率。
-
非结构化或半结构化数据存储:对于没有固定模式或结构的数据,传统的关系型数据库可能不太适用。HBase可以灵活地处理这类数据,不需要预先定义严格的表结构。
-
与Hadoop生态集成:如果你已经在使用Hadoop或相关的组件(如MapReduce、Spark等),HBase可以与这些工具无缝集成,方便地进行数据处理和分析。
-
高并发访问:对于需要处理大量并发读写请求的应用,HBase的分布式架构可以提供高并发处理能力,确保系统的稳定性和性能。
-
容错和可靠性要求:HBase建立在Hadoop HDFS之上,具有高度的容错性和可靠性。即使部分节点出现故障,数据也不会丢失,保证了数据的持久性和可用性。
综上所述,当面对大数据存储、实时读写、列式存储需求、非结构化或半结构化数据存储、与Hadoop生态集成、高并发访问以及容错和可靠性要求等场景时,可以考虑使用HBase作为解决方案。
怎么使用Hbase
Hbase的核心概念
HBase 是一个开源的非关系型分布式数据库(NoSQL),它运行在 Hadoop 分布式文件系统(HDFS)之上,是 Apache 的 Hadoop 项目的一部分。HBase 提供了对大规模数据集的随机实时读/写访问,并且是一个面向列的数据库,它通过列簇(Column Family)来存储数据。
以下是 HBase 中的一些核心概念:
-
列簇(Column Family):
- 在 HBase 中,列簇是表的一个逻辑分组,包含那些在存储和访问上拥有共同特性的列。数据在列簇级别进行压缩和存储,因此推荐将经常一起被访问的列放在同一个列簇中。
-
RowKey:
- RowKey 是 HBase 表中的主键,用于唯一标识每一行数据。它是一个二进制数组,可以是任意字符串,且在表中按照字典顺序进行排序。RowKey 的设计对于查询性能至关重要,因为 HBase 支持基于 RowKey 的单行查询和范围扫描。
-
Timestamp(时间戳):
- 每个单元格(Cell)中的数据都有一个时间戳,它允许 HBase 存储同一 RowKey 下的多个版本的数据。时间戳默认由 HBase 在数据写入时自动赋值,用户也可以自定义时间戳。
-
Cell:
- HBase 中的 Cell 是由行键、列簇、列限定符(Column Qualifier)和时间戳唯一确定的数据单元。Cell 中的数据未解析,全部以字节码形式存储。
-
Region:
- HBase 表的水平切片称为 Region,每个 Region 负责一定范围的 RowKey。随着数据量的增长,表可以分裂成更多的 Region 以支持数据的水平扩展。
-
HLog(Write-Ahead Log,预写日志):
- HLog 是 HBase 的一种日志系统,用于记录对数据库的所有修改操作,确保在系统故障时能够恢复数据。
-
HMaster 和 HRegionServer:
- HMaster 负责管理集群的元数据和监控所有 HRegionServer 的状态。HRegionServer 负责处理对数据的读写请求,以及与底层 HDFS 的交互。
-
HDFS(Hadoop Distributed File System):
- HBase 依赖于 HDFS 作为其底层存储系统,HDFS 提供了高可靠性和可扩展性的数据存储。
-
ZooKeeper:
- HBase 使用 ZooKeeper 来进行集群协调,如 RegionServer 的监控、元数据的入口以及集群配置的维护。
这些概念共同构成了 HBase 数据模型和架构的基础,使其能够有效地存储和处理大规模数据集。
Hbase的存储结构
HBase 是一个分布式的、面向列的数据库,其存储结构设计用于高效地处理大量数据。以下是 HBase 的主要存储结构组件:
-
HDFS (Hadoop Distributed File System):
- HBase 依赖于 HDFS 作为其底层存储系统。HDFS 负责数据的可靠存储,并将数据分散在多个廉价的硬件设备上,以实现高吞吐量的数据访问。
-
Table:
- HBase 中的表是数据的集合,类似于关系型数据库中的表。HBase 表不要求有预定义的模式,可以动态地添加列。
-
Region:
- HBase 表是水平分割的,每个分割的部分称为 Region。每个 Region 负责存储表中一定范围的行,由 RowKey 确定。当 Region 增长到一定大小后,会自动分裂成两个新的 Region,以保持系统的可扩展性。
-
Store:
- Store 是 Region 中的一个存储单元,对应于表中的一个列簇(Column Family)。Store 由 MemStore 和 StoreFile 组成。
-
MemStore:
- MemStore 是一种内存缓存,用于暂存最近写入的数据。当数据通过 HBase API 写入时,首先写入 MemStore,直到 MemStore 达到一定阈值后,数据会被刷新到 StoreFile。
-
StoreFile:
- StoreFile 是 MemStore 刷新到磁盘上的文件,以 HFile 格式存储。StoreFile 是不可变的,一旦创建,其内容就不会改变。
-
HFile:
- HFile 是 HBase 中的底层存储文件格式,用于存储键值对数据。HFile 支持快速的随机读取。
-
Compaction:
- 随着时间的推移,Store 中会积累许多小的 StoreFile,这会导致读取操作效率降低。因此,HBase 会定期执行 Compaction 操作,将多个 StoreFile 合并成少数几个大的 StoreFile。
-
HLog (Write-Ahead Log):
- HLog 是 HBase 的日志系统,用于记录对数据的所有变更操作。在数据写入 MemStore 之前,先写入 HLog,以确保在系统故障时能够恢复数据。
-
ZooKeeper:
- HBase 使用 ZooKeeper 进行集群协调,如监控 RegionServer 的状态、管理元数据等。
-
HMaster:
- HMaster 负责管理集群的元数据信息,监控所有 RegionServer 的状态,并负责 Region 的分配和负载均衡。
-
HRegionServer:
- HRegionServer 是 HBase 中负责处理客户端读写请求的进程,每个 HRegionServer 管理一部分表的 Region。
HBase 的存储结构设计允许它高效地处理大数据,并且具有良好的扩展性。通过 Region 的自动分裂和合并,以及 MemStore 和 StoreFile 的使用,HBase 能够支持高并发的数据读写操作。同时,HLog 保证了数据的持久性和一致性。
Hbase数据表特点
HBase 最基本的单元是列(colume),一个列或者多个列形成一行。
每个行(row)都拥有唯一的行键(row key)来标定这个行的唯一性。
每个列都有多个版本,多个版本的值存储在单元格(cell)中。
若干个列又可以被归类为一个列族。
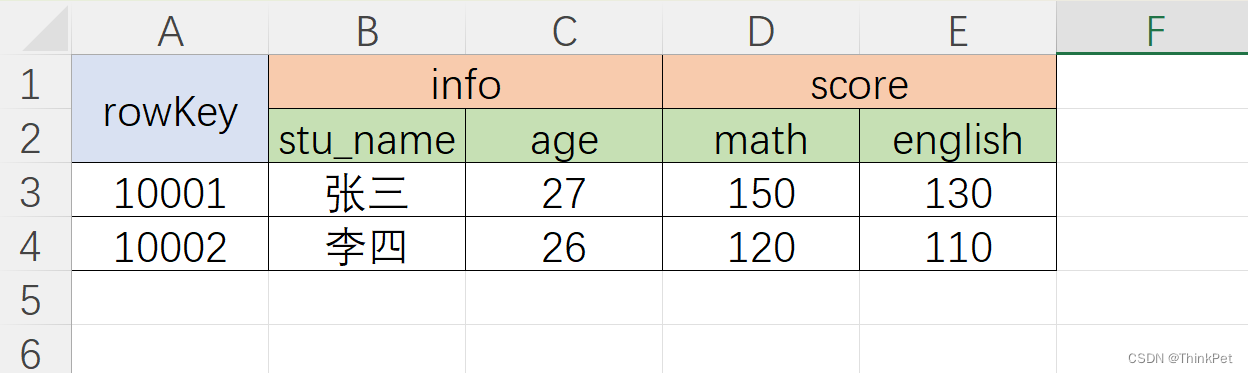
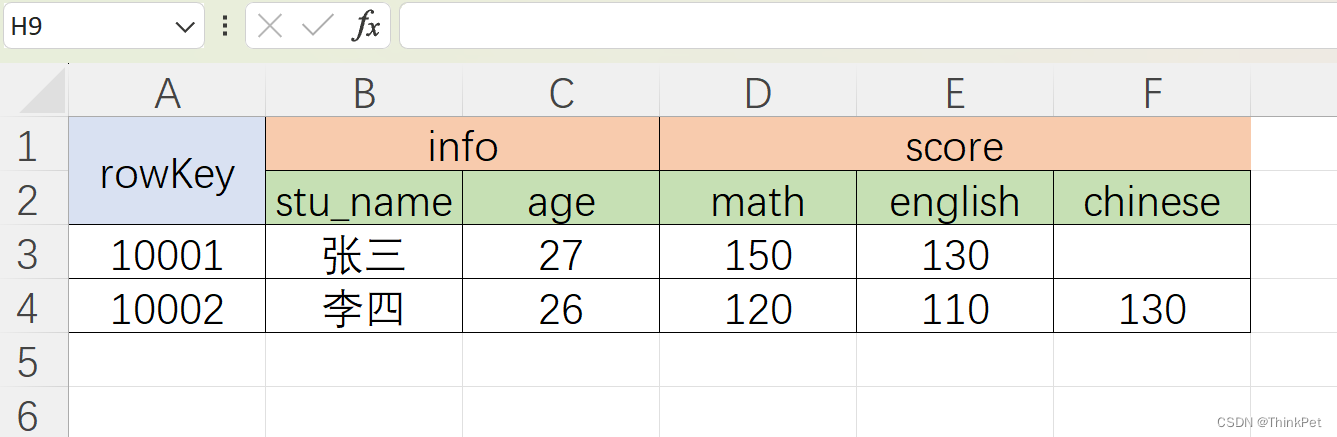
与传统的关系型数据库对比:
- 传统数据库是严格的行列对齐。比如这行有三列 a、b、c,下行肯定也有三列 a、b、c。其中每个行都是不可分割的,也就是说三个列必须在一起,而且要被存储在同一台机器上,甚至是同一个文件里面
- HBase 中行跟行的列可以完全不一样,比如这一行有三列 a、b、c,下一个行也许是 4 列 a、e、f、g。并且这个行的数据跟另一个行的数据也可以存储在不同的机器上,甚至同一个行内的列也可以存储在完全不同的机器上
- 行键(rowkey)
3.1 rowkey 类似 MySQL、Oracle 中的主键,不过它是由用户指定的一串不重复的字符串,规则随我们定义。在 HBASE 内部,RowKey 保存为字节数组
3.2 RowKey 可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes)
3.3 rowkey 决定这个 row 的存储位置。HBase 中无法根据某个 column 来排序,系统永远是根据 rowkey 来排序的,排序规则为:根据字典排序。因此设计 RowKey 时,要充分利用排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
3.4 访问 HBASE table 中的行,只有三种方式
3.4.1 通过单个 RowKey 访问
3.4.2 通过 RowKey 的 range(正则)
3.4.3 全表扫描 - 插入 HBase 的时候,如果用了之前已经存在的 rowkey 的话,会把之前存在的那个 row 更新掉。更新后之前存在的值并不会丢掉,而是会被放在这个单元格的历史记录里面,只是我们需要带上版本参数才可以找到这个值
- 列族(column family)
5.1 在 HBase 中,若干列可以组成列族。或者说表中的每个列,都归属于某个列族
5.2 建表的时候我们不需要指定列,因为列是可变的。但是一个表有几个列族必须一开始就定好
5.3 表的许多属性,比如过期时间、数据块缓存以及是否压缩等都定义在列族上,而不是定义在表或者列上
5.4 同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性
5.5 列名都以列族作为前缀。例如 courses:history、courses:math 都属于 courses 这个列族
5.6 列族存在的意义是:HBase 会把相同列族的列尽量放在同一台机器上。所以如果想让某几个列被放在一起,我们就要给他们定义相同的列族 - 单元格(cell)
6.1 虽然列已经是 HBase 的最基本单位,但一个列上可以存储多个版本的值,多个版本的值被存储在多个单元格里,多个版本之间用版本号(Version)来区分
6.2 唯一确认一条结果的表达式应该是“行键:列族:列:版本号”(rowkey:column family:column:version)
6.3 版本通过时间戳来索引。时间戳的类型是 64 位整型。这个时间戳默认由 Habse(在数据写入时自动)赋值,也可以由用户指定
6.4 每个 cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面
6.5 为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE 提供了两种数据版本回收方式。一是保存数据的最后 n 个版本,二是保存最近一段时间内的版本(比如最近七天)。 用户可以针对每个列族进行设置
使用docker部署Hbase
- 先部署并启动hbase容器
docker run -d -h docker-hbase -p 2181:2181 -p 8080:8080 -p 8085:8085 -p 9090:9090 -p 9000:9000 -p 9095:9095 -p 16000:16000 -p 16010:16010 -p 16201:16201 -p 16301:16301 -p 16020:16020 --name hbase harisekhon/hbase
- 进入hbase容器内部执行一些命令
执行 docker ps ,查看 【容器id】
执行 docker exec -it 【容器id】 bash ,进入到镜像内部的bash命令行
执行 hbase shell ,等待几秒,提示ok后
执行 exit
执行 hbase zkcli ,等待几秒,提示ok后
执行 exit
- 配置linux hosts文件
hosts文件中添加上
127.0.0.1 docker-hbase
- 先查询linux服务器ip ,然后配置win11 hosts文件
hosts文件中添加上
服务器ip docker-hbase
- 浏览器访问hbase web监控页面
http://docker-hbase:16010/master-status
在java代码中使用hbase-client操作hbase数据库
引入pom依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.3</version>
<exclusions>
<!-- 这里要排除一些依赖,否则会导致springboot报错 -->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
编写自定义HBaseConfig配置类
package org.example.demo2024.hbase;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* @program: demo24
* @description:
* @author: 作者名
* @create: 2024/04/23
*/
@Configuration
@ConfigurationProperties(prefix = "hbase")
public class HBaseConfig {
private Map<String, String> config = new HashMap<>();
public Map<String, String> getConfig() {
return config;
}
public void setConfig(Map<String, String> config) {
this.config = config;
}
public org.apache.hadoop.conf.Configuration configuration() {
org.apache.hadoop.conf.Configuration configuration = HBaseConfiguration.create();
for(Map.Entry<String, String> map : config.entrySet()){
configuration.set(map.getKey(), map.getValue());
}
return configuration;
}
@Bean
public Admin admin() {
Admin admin = null;
try {
Connection connection = ConnectionFactory.createConnection(configuration());
admin = connection.getAdmin();
} catch (IOException e) {